Việc này sẽ xóa trang "DOI". Xin vui lòng chắc chắn.
Obtaining a DOI (Digital Object Identifier)
You will first need to fork this repository on the G-node GIN instance, then you can follow their workflow, copied below.
Contents
- Summary
- Introduction
- Creating a DataCite metadata file
- Structuring the DataCite file
- Finalising the DOI request
Summary
- Create a repository
- Upload data (using the GIN Website, the command line client for all platforms, the Windows GUI client, or git/git-annex).
- Create a file called
datacite.ymlwhich contains information for publication of your data. - Make sure the repository is public
- Click the Request DOI button
Introduction
A DOI (Digital Object Identifier) permanently identifies a digital resource, allowing datasets or files to be citable and accessible through this identifier.
Obtaining a DOI constitutes a publication and therefore specific metadata must be provided to be stored in the DataCite DOI registry.
When using the GIN DOI service, this information must be in a file called datacite.yml at the root of the repository to be published.
The following section describes how this file can be created and which information it should contain.
You can find datasets already published with the GIN-DOI service at http://doid.gin.g-node.org.
Preparing your repository
Before submitting your DOI request, ensure that the README.md file for your repository is comprehensive and complete. This greatly helps anyone who wants to use your data. Consider including summaries of the repository contents and structure, information on how to access and use the data, links to related publications and author, licensing and funding information. A good example can be found here.
Creating a DataCite metadata file
To create the DataCite file, click the button labelled "Add DataCite File" at the top of the repository page (see image below). This will add the datacite.yml template file into your repository. You can then start editing the template with the information about your data.
Note that some, if not most, of the information that is requested for the DataCite file may also be useful to have in the README file describing the repository. This redundancy is ok as the DataCite information is for automated registration with the DOI database, while the README file is intended for human readers.
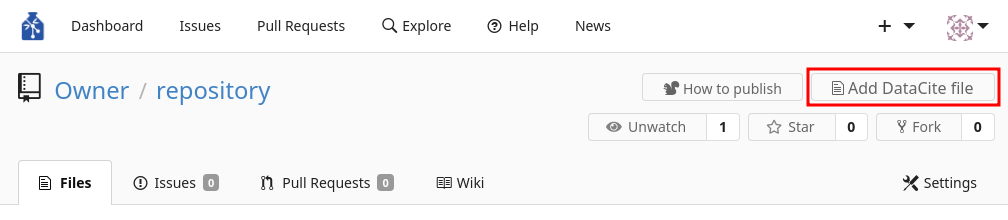
After clicking on the "Add DataCite File" button, you will be taken to an edit page where you can fill in the appropriate metadata for your dataset.
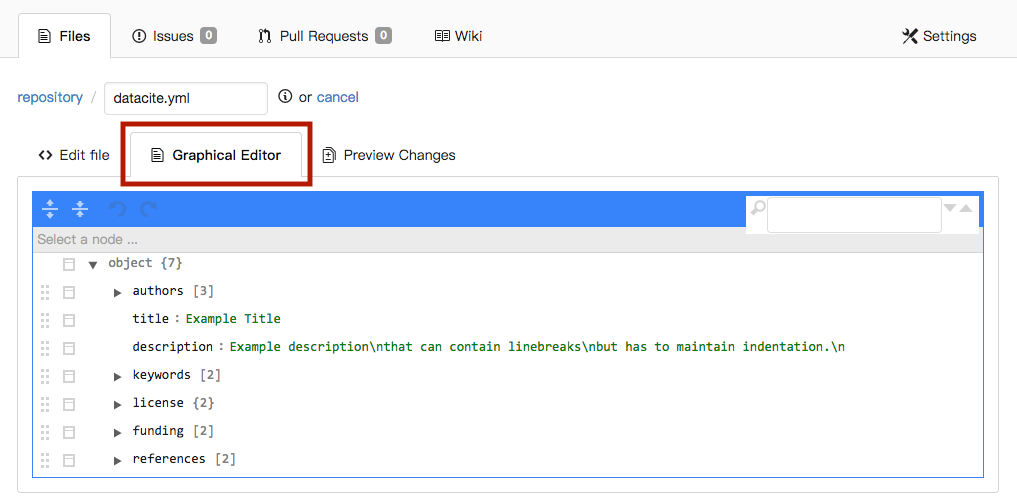
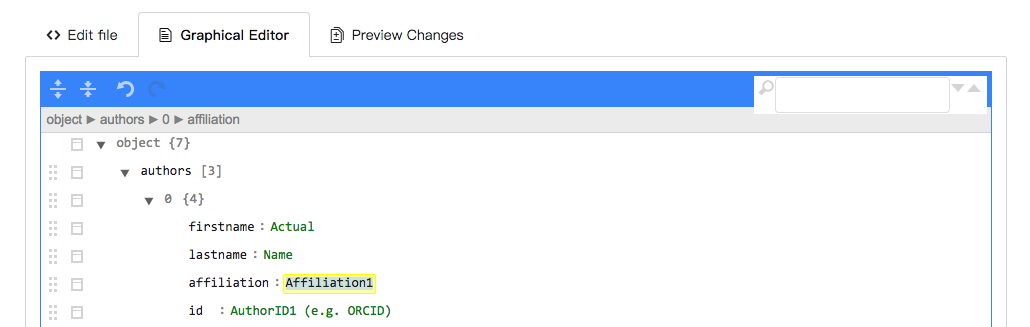
The Graphical Editor tab at the top of the file text will switch to a simpler representation of the file's content.
In this view, comments are removed, fields names are shown in black text, and field values are shown in green.
In the original Edit file view, the comments (lines beginning with # symbol) explain the meaning and format of each section.
You may remove these comments.
You can also find a description of the needed entries in the next section of this tutorial.
Clicking on the arrow next to an entry category will expand that section.

To change the order of entries, click on the dotted icon and drag to the desired position.

If you need more or fewer entries for any category, you can duplicate or delete the ones in the example file by clicking on the square icon.
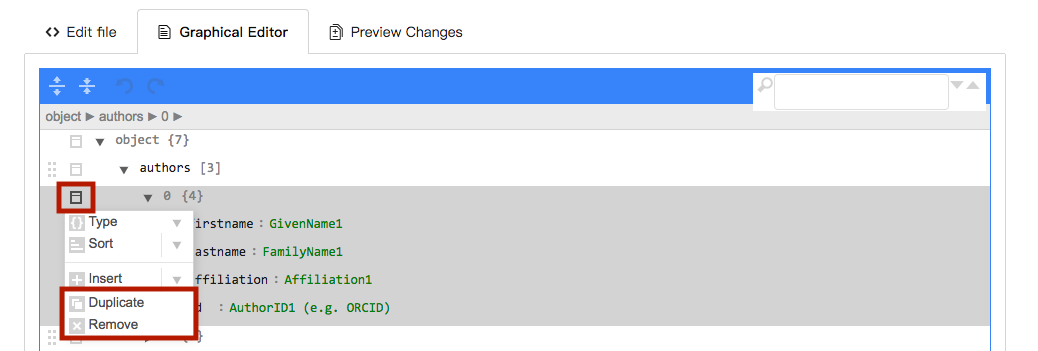
Modify the example entries by replacing the green text with the information that fits your repository data. Please remove any lines with example entries from the template that do not apply to your dataset.
After adding an appropriate commit message, click "Commit Changes" at the bottom of the page to save. Once saved or uploaded to the root of a repository, a valid file will be rendered below the Readme section in the repository overview.
Structuring the DataCite file
Required information
The datacite.yml file must contain at least the following entries:
authors
title
description
keywords
license
Optional information
These entries may also be used to provide additional information:
references
funding
Entries are specified by providing the corresponding lowercase keyword (authors, title, etc.) followed by a colon and contents formatted as described here and seen in the example file.
Authors
Authors are the main researchers involved in working on the data, or the authors of the publication in order of priority.
A first and last name are required.
Additionally, affiliation and ID (digital identifier, e.g. ORCID) are highly recommended.
Including an ORCID for example will automatically include the dataset publication in your ORCID record.
Please enter the authors as list items, each item indented and prefixed with -, each of the author keywords indented as shown below.
For the ID, you can include a prefix (followed by a colon :) to indicate the type of identifier, e.g., ORCID:, ResearcherID:.
authors:
-
firstname: "GivenName1"
lastname: "FamilyName1"
affiliation: "Affiliation1"
id: "ORCID:0000-0001-2345-6789"
-
firstname: "GivenName2"
lastname: "FamilyName2"
affiliation: "Affiliation2"
id: "ResearcherID:X-1234-5678"
-
firstname: "GivenName3"
lastname: "FamilyName3"
Title
The title is the descriptive name of the dataset to be published. Line breaks may not be used in the title field.
title: "Example Title"
Description
The description contains extended information about your dataset.
Line breaks may be used as long as indentation is maintained.
The pipe symbol | after the section heading indicates that this is a multi-line field.
We recommend this to be a few sentences long and have a similar role as a manuscript abstract. It is the text that may come up in the results of a web search.
description: |
Example description
that can contain linebreaks
but has to maintain indentation.
Keywords
The keywords entry should be used to list terms the dataset is associated with.
As many keywords as needed to appropriately characterise the dataset may be entered with each one being on a new line, indented and prefixed with -.
keywords:
- Neuroscience
- Electrophysiology
License
The license entry specifies the license under which the dataset will be published. Examples of open licenses are
CC0 (http://creativecommons.org/publicdomain/zero/1.0/)
CC-BY (http://creativecommons.org/licenses/by/4.0/)
More licenses and information about them can be found here.
Please provide both a license name and a URL to the original license text, both indented as shown in the example below. In addition, a LICENSE file with the text of the corresponding license needs to be present in the repository. The license file can either be selected when creating your repository or uploaded afterwards.
license:
name: "CC0"
url: "http://creativecommons.org/publicdomain/zero/1.0"
References
References are resources associated with the dataset, such as a research article that is based on the data. In addition to the name, please provide the relation to the dataset and, if possible, a digital identifier (e.g. DOI). If your dataset refers to a manuscript before publication and citation information or DOI are not known yet, enter any information that you have at the time. Once you know citation and DOI of the publication, please update the information in the datacite.yml file so that dataset and paper can be linked in the DataCite registry, which will increase the findability of your publications.
For id, add a prefix (followed by a colon :) to indicate the source/type of the identifier.
Supported sources are DOI, arXiv, and PMID (see examples below).
For reftype, the following relations may be used:
IsSupplementTo
IsDescribedBy
IsReferencedBy
The most common situation is referring to a manuscript that describes a study based on the data.
For these cases the appropriate reftype to use is IsSupplementTo.
For citation, please enter the full citation information (authors, year, title, journal, volume, pages).
This is somewhat redundant with the id if you provide one, but it will greatly help human readers to recognize your publications.
Please enter the references as list items with each item indented and prefixed with - and each of the keywords indented as shown below.
references:
-
id: "doi:10.xxx/zzzz"
reftype: "IsSupplementTo"
citation: "Citation1"
-
id: "arxiv:mmmm.nnnn"
reftype: "IsSupplementTo"
citation: "Citation2"
-
id: "pmid:nnnnnnnn"
reftype: "IsReferencedBy"
citation: "Citation3"
Funding
Funding is a list of items indicating any funding related to the dataset.
The funder name and grant number should be specified and separated by a comma.
Each item should be on a new line, indented and prefixed with -.
funding:
- "DFG, DFG.12345"
- "EU, EU.12345"
Finalising the DOI request
Once a valid DataCite file named datacite.yml has been uploaded to the root of a public repository, a preview of the contents will be rendered below the README section in the repository overview.
A DOI may now be requested by clicking the "Request DOI" button.
If the "Request DOI" button does not appear, this indicates that your repository does not fulfill the necessary requirements.
Make sure your DOI file is correct and that your repository is publicly accessible.
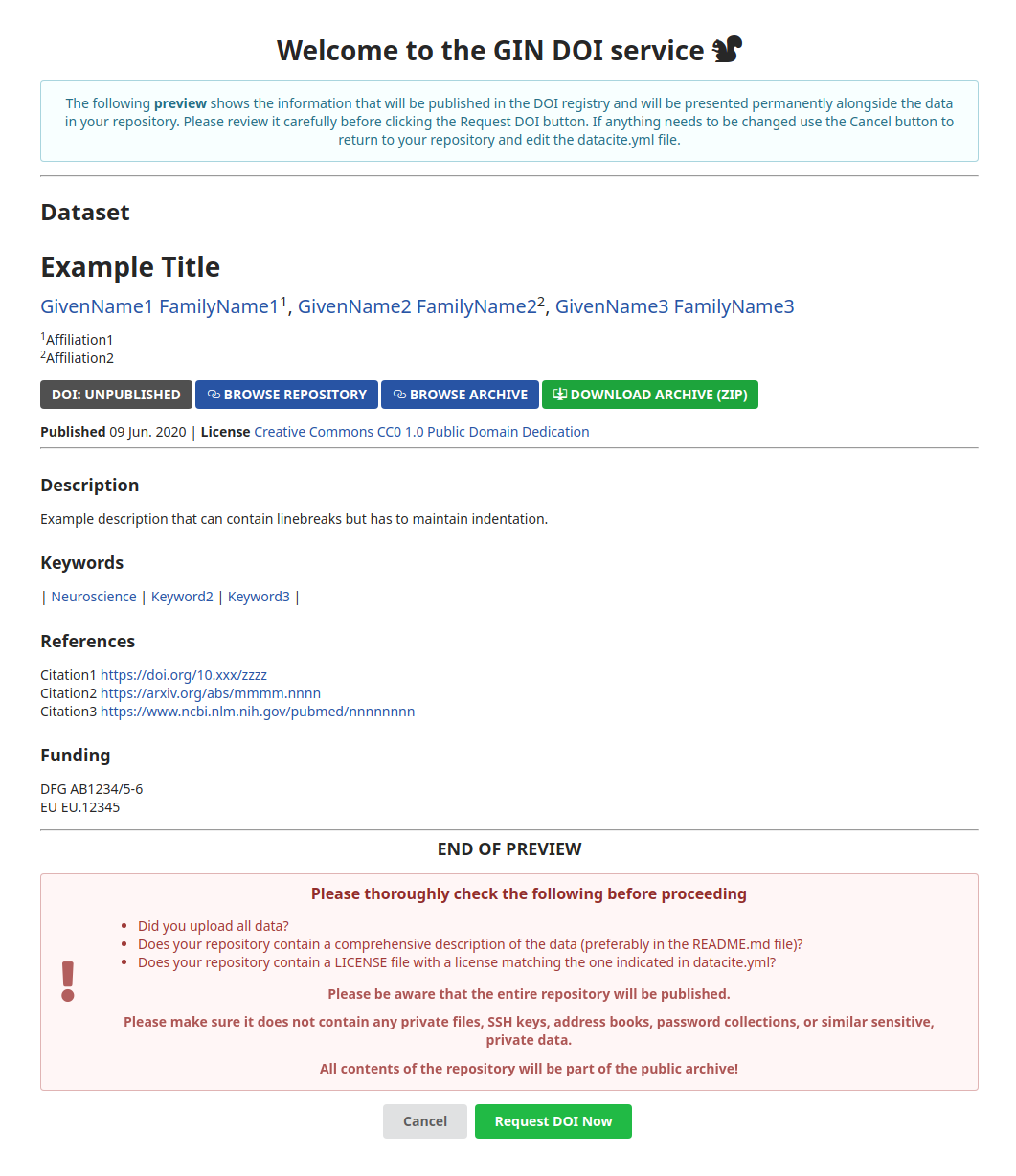
The DataCite file will be automatically checked for formatting and encoding errors. A preview is also displayed, allowing a final check for any mistakes. Once you have ensured that your DataCite file is correct, click the "Request DOI Now" button to submit your request.
Please note that all data contained in your repository will be archived for DOI registration. Any private files should thus be removed before submitting a DOI request.
Parts of the registration process are performed manually to ensure that they meet the minimal requirements to make the data useful for other researchers. You will be notified at the email address associated with your account on GIN once the registration is complete.
julien colomb đã chỉnh sửa trang này 5 năm trước cách đây
Xóa trang